545%!DeepSeek公布理論成本利潤率
過去一周,DeepSeek連續開放了5個Infra項目的源代碼,正當大家以為這場開源盛宴已經結束。3月1日,DeepSeek的彩蛋來了!開源周Day6,DeepSeek官方團隊在開發者社區Github和知乎給出了DeepSeek-V3/R1推理系統的技術解讀。通過優化吞吐和延遲,DeepSeek理論上一天的總收入達到了562027美元,成本利潤率為545%。
敏銳的網友——如MenloVentures投資人Deedy翻譯了這意味著什么:“理論ARR(年收入)2億美元、利潤率超過500%,這樣的商業效率理應是一家值100億美元的公司。
”從2024年5月發布DeepSeekV2以來,DeepSeek模型服務就以“價格屠夫”示眾,總是比行業其他模型便宜1/10左右,質疑DeepSeek虧本打價格戰的聲音也一直有。
通過這5天開放源代碼以及當下的推理系統概述,這一疑慮也被打消,可以預見,模型推理價格越來越負擔得起,且服務提供方也有的賺。這一事件的影響也可以通過社交平臺網友展現出刷屏的驚喜得以一窺,“成本利潤率545%,等于說你是在告訴我,我被Open AI搶奪了?開源周Day7的彩蛋是 AGI?”
但更大的信號指向生態伙伴,部署DeepSeek有的賺。
一位AI領域的投資人表示,“官方技術解讀表明,云平臺和上下游通過部署DeepSeek的服務,理論上收益和利潤率可以達到很高”。無論是對于提供在線推理、還是私有化部署等服務的供應商,都是利好。
在這波DeepSeek熱中受益的云平臺硅基流動創始人袁進輝也在首要時間發表了自己的感受,“DeepSeek官方披露大規模部署成本和收益,又一次顛覆了很多人認知。”但需要時間適配DeepSeek V3/R1模型架構,他表示“現在很多供應商還做不到這個水平,主要是V3/R1架構和其它主流模型差別太大了,由大量小專業人士組成,導致瞄準其它主流模型結構開發的系統都不再有效,必須按照DeepSeek報告描述的方法才能達到比較好的效率,而開發這樣的系統難度很高,需要時間”。
袁進輝進一步指出現在復現這樣的推理服務的難度以及DeepSeek可能的戰略思考,“幸好這周DeepSeek五連發已經把主要模塊開源出來了,降低了社區復現的難度。這些成果充分體現了DeepSeek團隊首要性原理的思考方式和強悍的意志,他們應該是首先是基于某些原因想到了用這樣的模型結構,然后發現這樣的結構無論是訓練還是推理,要做好都有非常大的工程挑戰,不過這些問題在他們工程團隊來說并不是搞不定的,關鍵是花那么大力氣做完是否有大的收益呢,在極終結果出來前,誰也說不準,他們還是賭了,結果是賭對了。也可能是反過來的,基于系統的出發點設計了這樣一個全新的模型結構。”
在DeepSeek官方報告中也提示了DeepSeek-V3/R1推理系統的優化目標是:更大的吞吐,更低的延遲。配合技術解讀,DeepSeek開源周放出的5個代碼庫帶來的影響力才剛剛開始。
《DeepSeek-V3 / R1 推理系統概覽全文
DeepSeek-V3/R1推理系統的優化目標是:更大的吞吐,更低的延遲。
為了實現這兩個目標,我們的方案是使用大規模跨節點專業人士并行(Expert Parallelism / EP)。首先EP使得batch size快速增加,從而提高GPU矩陣乘法的效率,提高吞吐。其次EP使得專業人士分散在不同的 GPU上,每個GPU只需要計算很少的專業人士(因此更少的訪存需求),從而降低延遲。
但EP同時也增加了系統的復雜性。復雜性主要體現在兩個方面:
EP引入跨節點的傳輸。為了優化吞吐,需要設計合適的計算流程使得傳輸和計算可以同步進行。
EP涉及多個節點,因此天然需要Data Parallelism(DP),不同的DP之間需要進行負載均衡。
因此,本文的主要內容是如何使用EP增大batch size,如何隱藏傳輸的耗時,如何進行負載均衡。
1、大規模跨節點專業人士并行(Expert Parallelism / EP)
由于DeepSeek-V3/R1的專業人士數量眾多,并且每層256個專業人士中只啟動其中8個。模型的高度稀疏性決定了我們必須采用很大的overall batch size,才能給每個專業人士提供足夠的expert batch size,從而實現更大的吞吐、更低的延時。需要大規模跨節點專業人士并行(Expert Parallelism / EP)。
我們采用多機多卡間的專業人士并行策略來達到以下目的:
Prefill:路由專業人士EP32、MLA和共享專業人士DP32,一個部署單元是4節點,32個冗余路由專業人士,每張卡9個路由專業人士和1個共享專業人士
Decode:路由專業人士EP144、MLA和共享專業人士DP144,一個部署單元是18節點,32個冗余路由專業人士,每張卡2個路由專業人士和1個共享專業人士
2、計算通信重疊
多機多卡的專業人士并行會引入比較大的通信開銷,所以我們使用了雙 batch重疊來掩蓋通信開銷,提高整體吞吐。
對于prefill階段,兩個batch的計算和通信交錯進行,一個batch在進行計算的時候可以去掩蓋另一個batch的通信開銷;
對于decode階段,不同階段的執行時間有所差別,所以我們把attention部分拆成了兩個stage,共計 5 個stage的流水線來實現計算和通信的重疊。
3、盡可能地負載均衡
由于采用了很大規模的并行(包括數據并行和專業人士并行),如果某個GPU的計算或通信負載過重,將成為性能瓶頸,拖慢整個系統;同時其他GPU因為等待而空轉,造成整體利用率下降。因此我們需要盡可能地為每個GPU分配均衡的計算負載、通信負載。
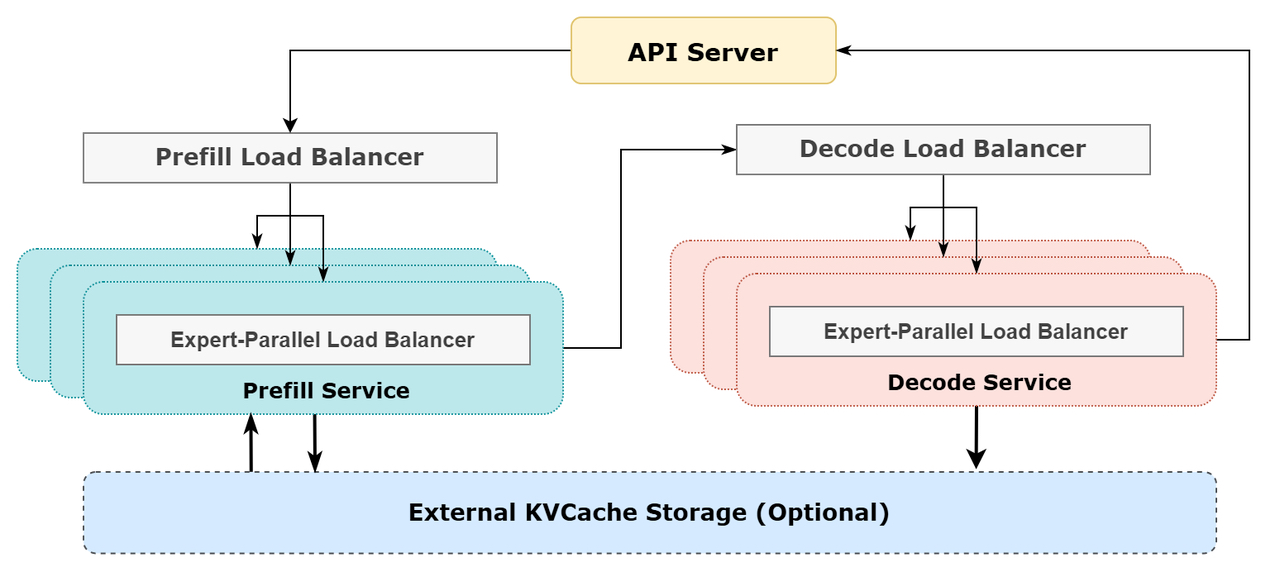
Prefill Load Balancer
重點問題:不同數據并行(DP)實例上的請求個數、長度不同,導致 core-attention 計算量、dispatch發送量也不同
優化目標:各GPU的計算量盡量相同(core-attention 計算負載均衡)、輸入的token數量也盡量相同(dispatch發送量負載均衡),避免部分GPU處理時間過長
Decode Load Balancer
重點問題:不同數據并行(DP)實例上的請求數量、長度不同,導致core-attention計算量(與KVCache占用量相關)、dispatch發送量不同
優化目標:各GPU的KVCache占用量盡量相同(core-attention計算負載均衡)、請求數量盡量相同(dispatch 發送量負載均衡)
Expert-Parallel Load Balancer
重點問題:對于給定 、MoE模型,存在一些天然的高負載專業人士(expert),導致不同GPU的專業人士計算負載不均衡
優化目標:每個GPU上的專業人士計算量均衡(即極小化所有 GPU 的dispatch接收量的極大值)
4、參考架構圖
5、線上系統的實際統計數據
DeepSeek V3和R1的所有服務均使用H800 GPU,使用和訓練一致的精度,即矩陣計算和dispatch傳輸采用和訓練一致的FP8格式,core-attention計算和combine傳輸采用和訓練一致的BF16,很大程度保證了服務效果。
另外,由于白天的服務負荷高,晚上的服務負荷低,因此我們實現了一套機制,在白天負荷高的時候,用所有節點部署推理服務。晚上負荷低的時候,減少推理節點,以用來做研究和訓練。在極近的24小時里(北京時間 2025/02/27 12:00 至 2025/02/28 12:00),DeepSeek V3和R1推理服務占用節點總和,峰值占用為278個節點,平均占用226.75個節點(每個節點為8個H800 GPU)。假定GPU租賃成本為2美元/小時,總成本為 $87072/天。
在24小時統計時段內,DeepSeek V3和R1:
輸入token總數為608B,其中342B tokens(56.3%)命中 KVCache 硬盤緩存。
輸出token總數為168B。平均輸出速率為20~22tps,平均每輸出一個token的KVCache長度是4989。
平均每臺H800的吞吐量為:對于prefill任務,輸入吞吐約 73.7k tokens/s(含緩存命中);對于decode任務,輸出吞吐約 14.8k tokens/s。
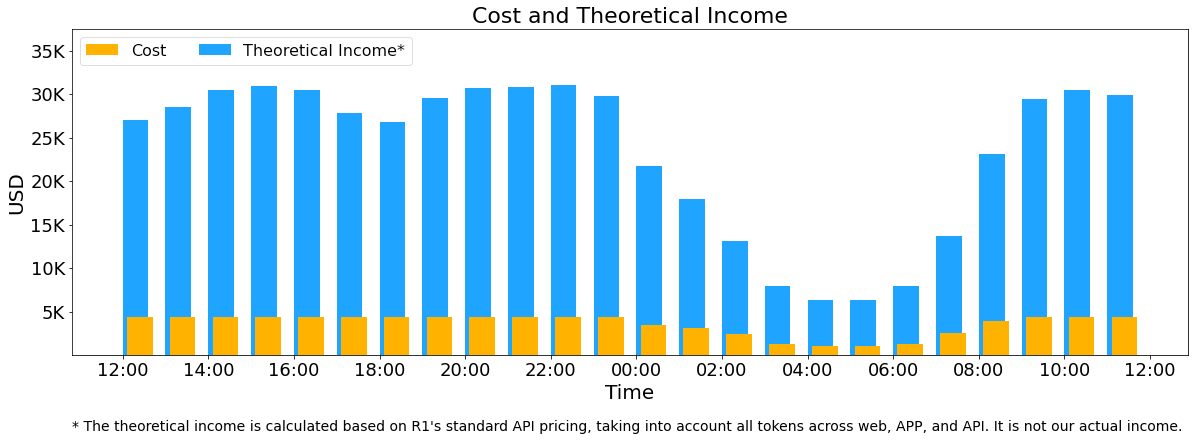
以上統計包括了網頁、APP 和 API 的所有負載。如果所有tokens全部按照DeepSeek R1的定價 (注:DeepSeek R1 的定價:$0.14 / 百萬輸入tokens (緩存命中),$0.55 / 百萬輸入tokens (緩存未命中),$2.19 / 百萬輸出 tokens;當然我們實際上沒有這么多收入,因為V3的定價更低,同時收費服務只占了一部分,另外夜間還會有折扣)計算,理論上一天的總收入為562027美元,成本利潤率545%。轉載自澎湃新聞
